How Do Deep Learning and Computer Vision Techniques Disrupt the Industries?

Computer vision companies develop computer vision platforms and models that can acquire, process, analyze and understand digital images. The aim of a computer vision system is to generalize and realize patterns and relations based on training data and to perceive and understand visual data automatically.
What Are Deep Learning and Computer Vision?
Machine learning technology is the heart of Artificial Intelligence (AI) technology. Machine learning enables computer systems to solve very complex problems, which cannot be solved by humans. Deep learning technology is part of machine learning. In other words, it is a class of machine learning algorithms.
These algorithms use a multi-layered system of filters to achieve hierarchical finding and retrieving of meaningful patterns. Each input layer obtains the output data of a previous layer ( i.e. the higher level patterns are derivatives of a lower level). Most of the deep learning algorithms are artificial neural networks of different kinds which consist of neurons just like their nature-made “cousins” in our brain.
What is the Neural Network in Machine Learning?
According to DeepAI, the artificial neural network is “a computational learning system that uses a network of functions to understand and translate a data input of one form into the desired output, usually in another form.” It is a learning system, which means it acts not only based on preset algorithms, but also on its own experience.
Neuron in deep learning is something similar to a “black box,” which has a lot of inputs and only one output. A neuron receives signals and forms an output signal based on them. The principles of output signal formation are governed by the inner algorithm. Such algorithms are modeled after the human brain and are designed to recognize patterns.
Neural networks interpret sensory data while labeling or clustering raw input. As Pathmind experts explain, “the patterns they recognize are numerical, contained in vectors, into which all real-world data, be it images, sound, text or time series, must be translated.” Neural networks cluster and classify your data, and group unlabeled data based on similarities among the sample inputs, and classify data based on training data sets. Neural networks can be regarded as a component of higher-scale machine learning applications.
Computer or machine vision technology is closely linked with AI technology as the computer has to interpret what it sees, analyze the information it gets through images, and act in accordance with the algorithm.
Computer vision image processing implies the actions similar to those a human performs when perceiving the world around through their eyes. According to Technopedia, “computer vision is a field of computer science that works on enabling computers to see, identify and process images in the same way that human vision does, and then provide appropriate output.”
How Does Computer Vision Work?
There are three basic steps:
1. Acquiring an image. The images necessary for analysis can be received through photo, video or even 3D technology
2. Processing the image. Deep learning models based on various algorithms automate the process, but models must be trained on large quantities of labeled or pre-identified images. This step is called deep learning education.
3. Understanding the image. This step implies data interpretation. Here the objects are identified, classified and clustered.
Computer Vision Platforms Application
Today’s computer vision platforms can be used in different ways depending on the goals they can perform:
- Facial recognition not only recognizes human faces in the image but identifies the personality of the individual.
- Image segmentation parses the image into pieces and analyzes each of them.
- Object detection identifies a specific object in the image.
- Pattern detection recognizes repeated patterns in images like colors and shapes.
- Edge detection identifies the outer edges of objects.
- Image classification groups images into categories.
- Feature matching pairs similarities in images to facilitate the classification process.
The goal of computer vision is to obtain useful results from the visual information received and processed. Based on this information, a computer can build 2D or 3D images that can be used, for instance, in the auto industries to inform drivers and help them analyze and react to situations on the road like traffic lights, road signs, pedestrians, other cars on the road, etc. or in retail, where the computer vision data received and analyzed can help maintain inventory on the shelves and/or in a warehouse, for example.
Does Computer Vision Use Machine Learning?
It does. The computer must be able to see objects, but also to understand what the objects are (i.e. classify, cluster, and analyze the data). To use deep learning solutions successfully you have to know how neural networks work and need to be able to select the type of network which suits your goals best and is able to tune such a network and select algorithms to get reliable and usable results.
How is Deep Learning Architecture Built?
The development of machine/deep learning infrastructure can be visualized like this:
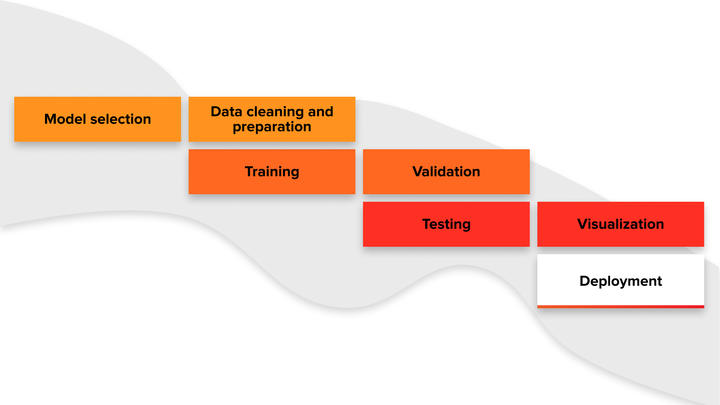
Every type of goal set for a computer vision application, such as voice recognition or image recognition, requires different algorithms. Selecting the right type of neural network and set of algorithms are the key computer vision challenges. To choose the right ones you have to involve a skilled computer vision engineer or data engineer.
This type of professional is very rare as this profession requires advanced mathematical skills and it is quite difficult to recruit such a pro. That is why computer vision companies try to market ready-made and integrated computer vision solutions.
For example, not long ago Amazon launched AutoGluon, an open-source library designed to enable developers to write AI-imbued apps with only a few lines of code. The service is intended to make machine learning tools available for common programmers. They can choose the objects for recognition and provide a set of data to train the system on and set the time of education, and the service automatically selects parameters and educates the system. (i.e. this solution allows you to eliminate the role of the data engineer, making computer vision more available to the masses).
Computer Vision Frameworks
Computer vision applications can be realized through the web with a camera in a browser using JavaScript, these also can be apps based on Python or C Sharp or mobile apps. Computer vision technology is especially popular in mobile apps as smartphones today are fitted with a camera and people are saturating the world with images and videos, computing power helps make the technology more accessible and affordable.
A simple example of a ready-made solution is Open CV, which is the most familiar open code library for almost every computer language used today. Open CV can detect objects, pick out and process images from visuals. Its basic algorithms can recognize the number of faces in an image, but to recognize the individuals, the data has to be sent to a server where machine learning algorithms look for matches in the available catalogs of faces. There are also ready solutions (neural networks) for facial recognition. You just have to launch the image database and educate the network.
Augmented reality (AR) and Virtual reality (VR) are hot topics in numerous industries overtaking large assets including smart money. AR and VR frameworks and programming languages are limited by available hardware solutions. Today’s AR/VR glasses are either too inconvenient or their working time or image quality is too poor.
Nevertheless, as soon as convenient and technically advanced hardware is on the market, these technologies will leapfrog into sophisticated solutions for business. Deep learning is on par with these technologies as it can bring a lot of value to the business while eliminating manual labor and the human factor. Deep learning allows the education of various computer vision platforms with functions that are performed by humans today. And this opens the door for more solutions which will save time, increase speed and accuracy, reduce cost, increase security and enhance the customer experience.
Cprime’s Experience in the Deep Learning Field
LayerJot, a B2B project currently under development, is applied in almost every industry where you want to eliminate manual labor requiring precision and attention. It is a platform for creating computer vision applications that can be trained for a specific field with basic functions such as recognition of objects in a certain space, counting of objects, performing associated actions when finding the object, etc.
Bottom Line
Computer vision is one of the most remarkable things to come out of the deep learning and artificial intelligence world. It is a good time to capitalize on the opportunities that deep learning and computer vision techniques open for your business.

